Транскрибация голосовых Telegram на VPS. Whisper.cpp, 1 CPU, 2GB RAM
Задача простая: получить голосовое сообщение из Telegram и превратить его в текст. Желательно без платных API, без GPU и без отдельной мощной машины. Для теста достаточно обычного VPS с одним ядром и двумя гигабайтами памяти. На таком сервере можно поднять whisper.cpp и принимать файлы через HTTP API.
Схема получается понятная. Сервер бота получает голосовое из Telegram. Потом он отправляет файл на VPS с транскрибацией. VPS распознаёт речь и возвращает JSON с текстом. После этого текст можно отправить в бота как обычную команду пользователя.
Это удобно для любого Telegram-бота. Пользователю не нужно печатать сообщение руками. Он может отправить короткое голосовое. Сервер распознаёт речь и возвращает обычный текст. Дальше бот обрабатывает его как стандартное сообщение.
Качество не идеальное. Whisper base на слабом VPS иногда ошибается в словах. Но общий смысл обычно понятен. При необходимости текст можно потом дополнительно почистить через GPT.
Что получилось по скорости
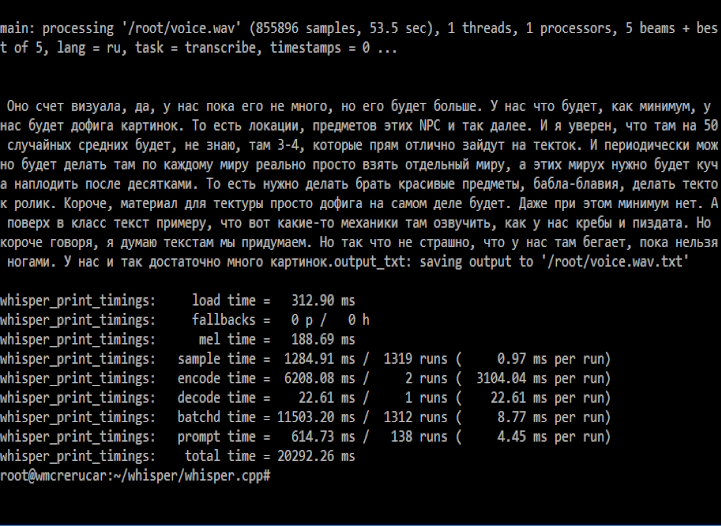
Тестовый файл длиной 53 секунды распознался примерно за 22 секунды. Это было на VPS с одним ядром и моделью base. Для коротких голосовых на 5-15 секунд задержка будет меньше. Поэтому лучше ограничить голосовые до 30-60 секунд.
Пример результата API:
{
"duration": 53.5,
"ok": true,
"processing_ms": 22184,
"text": "Оно счет визуала, да, у нас пока его не много..."
}
Технические детали
Сервер: VPS от Бегет:
CPU: 1 ядро, 3-3.3 GHz
RAM: 2 ГБ
Диск: 15 ГБ NVMe
Swap: 2 ГБ
OS: Ubuntu
Распознавание: whisper.cpp
Модель: ggml-base.bin
API: Flask + gunicorn
Порт API: 8091
Формат входа: ogg/opus из Telegram
Формат ответа: JSON
Установка whisper.cpp
Сначала создаём папку проекта. Потом включаем swap. Swap нужен как страховка от нехватки памяти. После перезагрузки он должен включаться сам.
mkdir -p /root/whisper
cd /root/whisper
sudo fallocate -l 2G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
grep -q '^/swapfile ' /etc/fstab || echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
Если swap уже был создан раньше, команда mkswap может ругнуться. В таком случае можно просто проверить состояние. В норме должно быть около 2 ГБ памяти и 2 ГБ swap.
swapon --show
free -h
Проверить размер диска можно так. После смены тарифа 15 ГБ могут отображаться как 14G. Это нормально для Linux.
df -h /
Сборка whisper.cpp
Теперь ставим зависимости. ffmpeg нужен для конвертации Telegram voice. Telegram обычно отдаёт голосовые как ogg/opus. Для Whisper удобнее сначала переводить их в wav.
git clone https://github.com/ggml-org/whisper.cpp
cd whisper.cpp
sudo apt update
sudo apt install build-essential git cmake ffmpeg wget curl -y
mkdir build
cd build
cmake ..
cmake --build . --config Release -j1
Флаг -j1 важен для слабого VPS. Он говорит собирать проект в один поток. Так сборка идёт медленнее. Зато меньше риск упереться в память.
Скачивание модели base
Для русского языка нужна обычная multilingual-модель. Не нужно брать модели с суффиксом .en. Они рассчитаны на английский язык. Для теста на 2 ГБ RAM нормально подошла base.
cd /root/whisper/whisper.cpp
bash ./models/download-ggml-model.sh base
Проверяем, что модель скачалась. Размер base-модели около 142 МБ.
ls -lh /root/whisper/whisper.cpp/models/ggml-base.bin
ls -la /root/whisper/whisper.cpp/build/bin/
Ручная проверка на voice.ogg
Для первого теста кладём файл сюда. Это может быть обычное голосовое из Telegram. Главное, чтобы файл был доступен на сервере.
/root/voice.ogg
Конвертируем ogg в wav. Частота 16000 и один канал подходят для распознавания. Это стандартный удобный формат для такой задачи.
ffmpeg -y -i /root/voice.ogg -ar 16000 -ac 1 -c:a pcm_s16le /root/voice.wav
Запускаем распознавание. Флаг -l ru задаёт русский язык. Флаг -nt убирает таймкоды. Флаг -otxt создаёт текстовый файл рядом с wav.
/root/whisper/whisper.cpp/build/bin/whisper-cli \
-m /root/whisper/whisper.cpp/models/ggml-base.bin \
-f /root/voice.wav \
-l ru \
-nt \
-otxt
Смотрим результат. Файл появится рядом с исходным wav.
cat /root/voice.wav.txt
API для транскрибации
Ручной запуск работает, но если бот леджит на другом сервере - нужен HTTP API. Сервер бота должен отправить файл и получить JSON. Для этого поднимем маленький Flask-сервис. Он будет слушать порт 8091.
Важный момент: на VPS уже может работать другой gunicorn. Например, старое приложение может слушать порт 8080. Его трогать не нужно. Новый API поднимаем отдельно на 8091.
ss -tulpn | grep LISTEN
ss -tulpn | grep 8091
Если порт 8091 свободен, продолжаем. Создаём отдельную папку и виртуальное окружение. Это не сломает другие Python-приложения на сервере.
mkdir -p /root/stt_api
cd /root/stt_api
sudo apt install python3-venv -y
python3 -m venv venv
/root/stt_api/venv/bin/pip install flask gunicorn
Файл /root/stt_api/app.py
Создаём файл приложения. Внутри есть проверка токена. Есть лимит размера и длительности файла. Также есть lock, чтобы Whisper не запускался параллельно.
nano /root/stt_api/app.py
import os
import time
import uuid
import fcntl
import subprocess
from flask import Flask, request, jsonify
app = Flask(__name__)
app.json.ensure_ascii = False
API_TOKEN = os.environ.get("STT_API_TOKEN", "CHANGE_ME")
TMP_DIR = "/tmp/stt_api"
LOCK_FILE = "/tmp/stt_api.lock"
WHISPER_BIN = "/root/whisper/whisper.cpp/build/bin/whisper-cli"
MODEL_PATH = "/root/whisper/whisper.cpp/models/ggml-base.bin"
MAX_FILE_SIZE = 10 * 1024 * 1024
MAX_DURATION = 60
os.makedirs(TMP_DIR, exist_ok=True)
def run_cmd(cmd, timeout):
p = subprocess.run(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
timeout=timeout
)
return p.returncode, p.stdout, p.stderr
def get_duration(path):
code, out, err = run_cmd([
"ffprobe",
"-v", "error",
"-show_entries", "format=duration",
"-of", "default=noprint_wrappers=1:nokey=1",
path
], 30)
if code != 0:
return None
try:
return float(out.strip())
except Exception:
return None
def clean_text(text):
lines = []
for line in text.splitlines():
line = line.strip()
if line:
lines.append(line)
return " ".join(lines).strip()
@app.route("/health", methods=["GET"])
def health():
return jsonify({
"ok": True,
"service": "stt"
})
@app.route("/transcribe", methods=["POST"])
def transcribe():
started = time.time()
token = request.headers.get("X-STT-Token", "")
if token != API_TOKEN:
return jsonify({
"ok": False,
"error": "unauthorized"
}), 401
if "voice" not in request.files:
return jsonify({
"ok": False,
"error": "voice file is required"
}), 400
voice = request.files["voice"]
request_id = str(uuid.uuid4())
ogg_path = os.path.join(TMP_DIR, request_id + ".ogg")
wav_path = os.path.join(TMP_DIR, request_id + ".wav")
txt_path = wav_path + ".txt"
try:
voice.save(ogg_path)
if os.path.getsize(ogg_path) > MAX_FILE_SIZE:
return jsonify({
"ok": False,
"error": "file too large"
}), 400
duration = get_duration(ogg_path)
if duration is None:
return jsonify({
"ok": False,
"error": "cannot read audio duration"
}), 400
if duration > MAX_DURATION:
return jsonify({
"ok": False,
"error": "voice is too long",
"duration": duration,
"max_duration": MAX_DURATION
}), 400
with open(LOCK_FILE, "w") as lock:
fcntl.flock(lock, fcntl.LOCK_EX)
code, out, err = run_cmd([
"ffmpeg",
"-y",
"-i", ogg_path,
"-ar", "16000",
"-ac", "1",
"-c:a", "pcm_s16le",
wav_path
], 60)
if code != 0:
return jsonify({
"ok": False,
"error": "ffmpeg failed",
"details": err[-1000:]
}), 500
code, out, err = run_cmd([
WHISPER_BIN,
"-m", MODEL_PATH,
"-f", wav_path,
"-l", "ru",
"-nt",
"-otxt"
], 180)
if code != 0:
return jsonify({
"ok": False,
"error": "whisper failed",
"details": err[-1000:]
}), 500
if not os.path.exists(txt_path):
return jsonify({
"ok": False,
"error": "text file not created"
}), 500
with open(txt_path, "r", encoding="utf-8", errors="ignore") as f:
text = clean_text(f.read())
return jsonify({
"ok": True,
"text": text,
"duration": duration,
"processing_ms": int((time.time() - started) * 1000)
})
except subprocess.TimeoutExpired:
return jsonify({
"ok": False,
"error": "timeout"
}), 504
except Exception as e:
return jsonify({
"ok": False,
"error": "internal error",
"details": str(e)
}), 500
finally:
for path in [ogg_path, wav_path, txt_path]:
try:
if os.path.exists(path):
os.remove(path)
except Exception:
pass
Ручной запуск API
Сначала запускаем API прямо в консоли. Это удобно для проверки. Пока консоль открыта, сервис работает. После Ctrl+C он остановится.
cd /root/stt_api
STT_API_TOKEN='rw_stt_uycok7qP2vLx4Zt8ou8co6r8sF0aCw5jErU' /root/stt_api/venv/bin/gunicorn \
-w 1 \
-b 0.0.0.0:8091 \
--timeout 240 \
app:app
Проверяем health endpoint. Это можно сделать на самом сервере. Также можно проверить с компьютера по внешнему IP.
curl http://127.0.0.1:8091/health
curl http://VPS_IP:8091/health
Ожидаемый ответ. Это значит, что Flask API поднялся.
{"ok":true,"service":"stt"}
Проверка транскрибации через curl
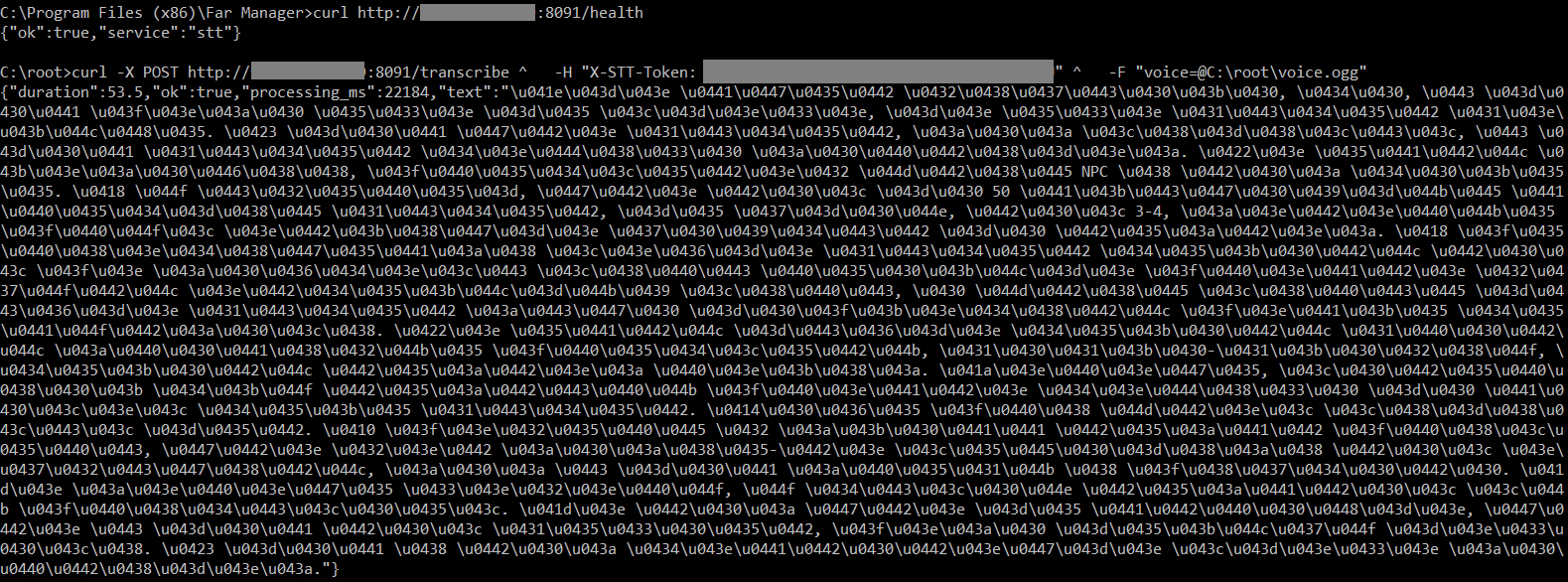
На Linux проверка выглядит так. Файл voice.ogg должен лежать на сервере. Токен должен совпадать с STT_API_TOKEN.
curl -X POST http://127.0.0.1:8091/transcribe \
-H "X-STT-Token: rw_stt_uycok7qP2vLx4Zt8ou8co6r8sF0aCw5jErU" \
-F "voice=@/root/voice.ogg"
В Windows cmd лучше писать одной строкой. Так меньше проблем с переносами и символом ^.
curl -X POST http://VPS_IP:8091/transcribe -H "X-STT-Token: rw_stt_uycok7qP2vLx4Zt8ou8co6r8sF0aCw5jErU" -F "voice=@C:\root\voice.ogg"
Ответ должен прийти в JSON. Поле text содержит распознанный текст. Поле duration показывает длину аудио. Поле processing_ms показывает время обработки.
{
"duration": 53.5,
"ok": true,
"processing_ms": 22184,
"text": "Оно счет визуала, да, у нас пока его не много..."
}
Почему есть очередь
На слабом VPS нельзя запускать несколько Whisper одновременно. Два параллельных распознавания не ускорят работу. Они просто забьют процессор и память. Поэтому API обрабатывает запросы по одному.
За это отвечают две вещи. Во-первых, gunicorn запускается с одним worker. Во-вторых, внутри app.py есть файловый lock. Даже при случайном увеличении worker модель не запустится параллельно.
-w 1
fcntl.flock(lock, fcntl.LOCK_EX)
Если несколько пользователей бота отправят голосовые одновременно, запросы встанут в очередь. Первый будет распознаваться сразу. Второй дождётся завершения первого. Для чата это безопаснее, чем параллельная обработка.
Запуск API через systemd
После проверки ручной запуск нужно остановить. Для этого нажимаем Ctrl+C. Потом создаём systemd-сервис. Он будет запускать API в фоне.
nano /etc/systemd/system/stt-api.service
[Unit]
Description=STT API
After=network.target
[Service]
WorkingDirectory=/root/stt_api
Environment=STT_API_TOKEN=rw_stt_uycok7qP2vLx4Zt8ou8co6r8sF0aCw5jErU
ExecStart=/root/stt_api/venv/bin/gunicorn -w 1 -b 0.0.0.0:8091 --timeout 240 app:app
Restart=always
RestartSec=3
[Install]
WantedBy=multi-user.target
Запускаем сервис. Команда enable нужна для автозапуска после перезагрузки. Status показывает, поднялся ли сервис.
systemctl daemon-reload
systemctl enable stt-api
systemctl start stt-api
systemctl status stt-api
Проверяем, что API снова отвечает. Теперь он работает уже в фоне.
curl http://127.0.0.1:8091/health
Логи можно смотреть так. Это полезно при ошибках ffmpeg, whisper или токена.
journalctl -u stt-api -f
PHP-запрос с сервера бота
На сервере бота нужен обычный POST-запрос. Файл отправляется как multipart/form-data. В заголовок передаётся секретный токен. В ответ приходит JSON с текстом.
<?php
function transcribeVoice($file_path)
{
$url = 'http://VPS_IP:8091/transcribe';
$token = 'rw_stt_uycok7qP2vLx4Zt8ou8co6r8sF0aCw5jErU';
if (!file_exists($file_path)) {
return array(
'ok' => false,
'error' => 'file not found'
);
}
$ch = curl_init();
$data = array(
'voice' => new CURLFile($file_path)
);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
'X-STT-Token: ' . $token
));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT, 300);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$response = curl_exec($ch);
if ($response === false) {
$error = curl_error($ch);
curl_close($ch);
return array(
'ok' => false,
'error' => $error
);
}
$http_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
$json = json_decode($response, true);
if (!is_array($json)) {
return array(
'ok' => false,
'error' => 'bad json',
'http_code' => $http_code,
'raw' => $response
);
}
$json['http_code'] = $http_code;
return $json;
}
$res = transcribeVoice('/path/to/voice.ogg');
if (!empty($res['ok'])) {
$text = $res['text'];
echo $text;
} else {
print_r($res);
}
?>
Как это подключается к Telegram
В webhook Telegram приходит message.voice.file_id. По file_id нужно вызвать getFile. Потом скачать файл с серверов Telegram. Полученный ogg отправляется в STT API.
Telegram webhook
→ message.voice.file_id
→ getFile
→ download voice.ogg
→ POST /transcribe
→ JSON с text
→ отправка текста в бота
Для первого теста можно делать всё синхронно. Пользователь бота отправил голосовое и ждёт ответ. Но в боевом режиме лучше сразу отвечать: «Распознаю голос». После транскрибации можно отправить отдельное сообщение с результатом.
Ограничения
Для такого VPS лучше ограничить голосовые до 60 секунд. Оптимально держать лимит около 30 секунд. Длинные голосовые будут занимать очередь. В чате это может мешать другим пользователям.
MAX_FILE_SIZE = 10 * 1024 * 1024
MAX_DURATION = 60
Если качество base окажется слабым, можно пробовать модели крупнее. Но на 2 ГБ RAM это уже рискованнее. Если скорость важнее качества, можно скачать tiny. Для чата иногда tiny тоже достаточно.
cd /root/whisper/whisper.cpp
bash ./models/download-ggml-model.sh tiny
Потом в app.py нужно заменить путь модели. Остальной код менять не нужно.
MODEL_PATH = "/root/whisper/whisper.cpp/models/ggml-tiny.bin"
Итог
На обычном VPS без GPU можно поднять рабочую транскрибацию. Для русского языка модель base даёт понятный результат. Ошибки в словах бывают, но смысл обычно сохраняется. Для Telegram-бота этого уже достаточно.
Главная польза схемы в том, что сервер бота остаётся лёгким. Он только скачивает голосовое и отправляет файл на STT VPS. Тяжёлая часть живёт отдельно. Потом такой сервис можно перенести на более мощную машину без переписывания бота.