Запуск LLM на VPS без GPU. 1 CPU, 1GB RAM
А можно ли поднять на 1Гб оперативы и 1 ядре llm модель, чтобы она хоть что-то связанное генерила? Конечно, можно. Вопрос - зачем. И на него есть ответ.
Допустим, у тебя куплена vps под какие-то личные задачи.. ну, не знаю, сайтик, например, на ней крутится или что-то страшное из трех букв. И юзается это редко, допустим, а в остальное время мощи по сути простаивают или задействованы не полностью. Расточительство, ведь. Что можно сделать, если там еще и llm-ка будет крутиться? ну.. слабой нейронкой много не нагенеришь качественного.. зато вот соотносить короткие текста по категориям она вполне может. Допустим, у тебя есть в тг чатик и там много спама. Нейронка нашего уровня вполне сможет анализировать сообщения на предмет спама и удалять хлам. Можно, конечно, анализировать и по бан-словам или по наличию ссылок.. но нейронка сможет прочекать более изощренные способы спама, нежелательных в чате нарративов или сомнительных предожений заработать. Также такая LLM вполне справится с извлечением информации или категоризацией. Я не говорю про "достать из текста телефон", с этим и регулярка справится. Я о более сложных случаях, если входящие сообщения нужно раскидывать по разным целям, мониторить сообщения на определенную тему или приводить к единому формату, например, "цена, тип объекта, контакт и т.д."
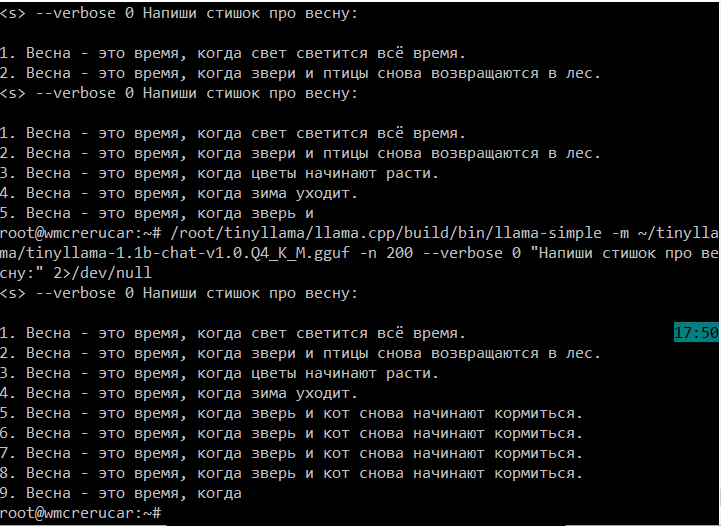
Итак, зверь поставлен (все команды по установке ниже). Что по итогам? Быстро? Качествено? Блэкджек и т.д? Ну.. на текущем железе, а это, повторюсь, vps с 1 ядром и 1gb оперы - слов 4-5 в секунду. Ну а качество - прям так себе. При этом на разных задачах ведет себя по разному. И когда ее клинит - начинает зацикливать текст. Так что не стоит от нее ожидать много. При этом, ответить на вопрос является ли текст спамом или нет - т.е. сненерировать одно слово - она вполне может. Т.е. для простых задач по фильтрации, категоризации небольших порций контента (типа постов) вполне подойдет.
Технические детали
Модель поднималась на VPS от Бегет:
Процессор: 1 виртуальное ядро Intel Xeon
Оперативная память: 1 ГБ
Swap: 2 ГБ
OS: Ubuntu 20.04 LTS
Модель: TinyLlama-1.1B-Chat, квантование Q4_K_M
Команды для запуска модели
mkdir tinyllama
cd tinyllama
sudo fallocate -l 2G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
grep -q '^/swapfile ' /etc/fstab || echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
sudo apt update
sudo apt install build-essential git cmake -y
mkdir build
cd build
cmake ..
make
wget https://huggingface.co/TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF/resolve/main/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf -O ~/tinyllama/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf
/root/tinyllama/llama.cpp/build/bin/llama-simple -m ~/tinyllama/tinyllama-1.1b-chat-v1.0.Q4_K_M.gguf -n 200 --verbose 0 "Пример простого вывода текста для проверки модели" 2>/dev/null